Article Summary For Social Sharing
Text summarization is a common branch of NLP where a corpus of text is reduced to compact pieces of text without compromising the key ideas of the source content. Given the explosion of written content, there is a growing need for summarization. Readers will find summarization useful when they need to quickly understand pieces of text as they go about carrying out related tasks.
There are two types of summarization - extractive and abstractive. Extractive summarization scores sentences in an article and chooses the highest ranked phrases as concise pieces of text that underscore the meaning of the source text. However, it does so by mostly extracting sentences directly from the content to produce a summary, so the exact words are used. Much of the applied work on text summarization today is done on extractive summarization.
Abstractive summarization examines the source text and produces an original cohesive summary without necessarily relying on existing words from the source text, while still retaining the critical key ideas.
I have built a data app that uses an extractive summarization technique - TextRank - to generate summaries that a user can paste on their LinkedIn feeds. Sometimes I would scroll around on LinkedIn and find that the users would quote a phrase from a technical article or write their own thoughts along with the article URL. This would be an applicable use case where text summarization can reduce the time it takes to help users get their points across when engaging in social sharing.
Data app is deployed and can be accessed here.
You can find the repository here.
Implementation
The data app uses the TextRank algorithm to compute the summaries of an article. TextRank is derived from PageRank in that instead of ranking web pages, it is ranked by sentences. By converting sentences to word embeddings and computing their cosine similarity matrix scores, they would then be converted into a graph with sentences as vertices and edges as the scores. These scores represent the sentence rankings. For this use case, I limited the number of summaries of up to three so that users will not be overwhelmed with summaries to choose.
The library used for this is the “summa summarizer”. It optimizes the similarity function and allows for control and configure different parameters in summarizing an article. This includes number of words, length as a proportion of the text, or even in a different language (for source text only). The app is written in Flask.

Challenges
Initially, I had planned for the text summarizer to produce a fixed number of summaries - 10. However, when I entered an article URL into the app in development I got a ‘list out of range’ error when the number of summaries produced was fewer than 10. As such, I removed the restriction and allowed the summarizer to generate as many summaries as needed - more or less than 10. Later on, I further tweaked the use case by allow the summarizer to produce up to 3 summaries, so that users are not overwhelmed with choices to make. I also wrote a conditional to check in advance how many summaries are formed. If there are no summaries, the application would output an error on the front-end. Otherwise it will output up to 3 summaries for users to choose.
I had also originally considered making the summarizer to be only for posting summary posts on Twitter, however this proven to be unfeasible as the length of a summary can vary. Currently the summanlp allows for the length of summary returned in terms of number of words or a fraction of the source content. I generalized the use case to allow for posting on Facebook and LinkedIn. A user can still post a summary post on Twitter, but he/she would need to be sure that the number of characters is not greater than 140.
Some thoughts for Improvement
As stated in the beginning of the article, there are two categories of summarization: extractive and abstractive. Extractive summarization uses computes weights for words and phrases in each sentence and then ranks them by similarity scores. Often, the words in such summaries are used verbatim. As well, I would like to introduce some text cleaning to the summaries generated to remove non-alphanumeric characters for improved readability.
In most business use cases, summaries are shortened, paraphrased, and compacted, so usually new words of combinations of phrases are used, and progress is started to head towards that direction. One area of improvement I am considering for applying to the application is using an abstractive summarization model that can produce realistic, relevant summaries that are very close to human-level written summaries.
Google AI has recently released a new model called the Text-To-Text Transfer Transformer (T5). The T5 is a new general purpose model that uses transfer learning to produce state of the art results across domains including machine translation, Q&A (without access to outside text sources), text classification, language modelling, and abstractive text summarization.
Image from Google AI’s blog post:
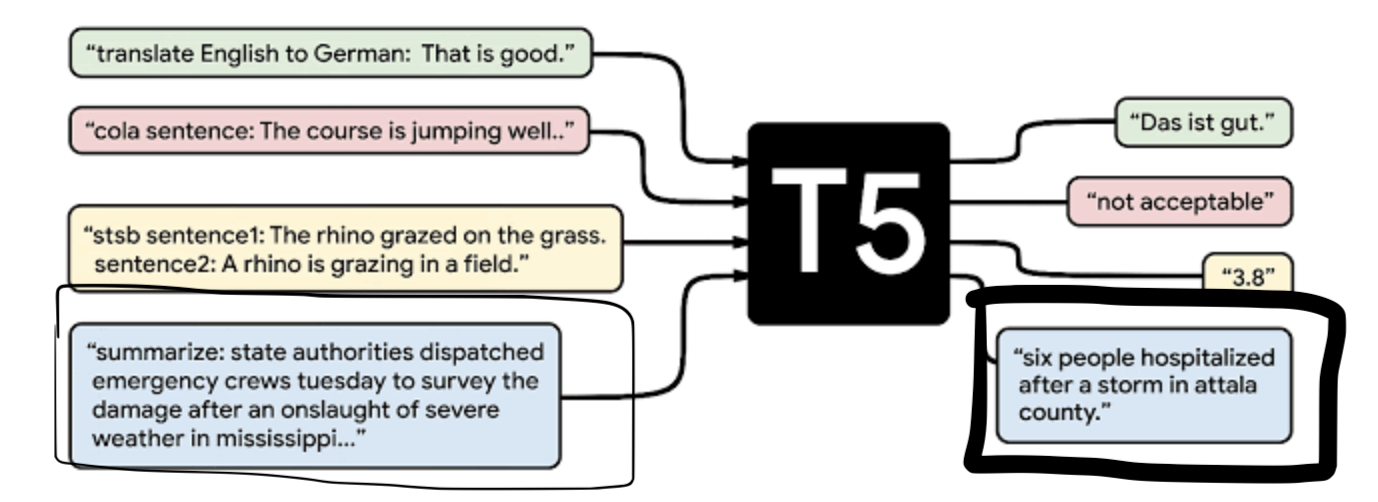
The T5 is a text-to-text model where the inputs and outputs will be text strings rather than just labels or spans of input. With its largest variant having 11 billion parameters from transfer learning on the large C4 pre-trained dataset, the T5 can produce meaningful output without much configuration required, although data scientists and machine learning engineers are free to do so as they wish.
To implement this model in our project, the plan would be to configure and train it for summarizing text. Once the model has demonstrated SOTA summarization results, this would then be replaced in the application for users ready to generate a complete, cohesive summary.
Besides using a transformer model for meaningful summarization, I would like to experiment with summarization in different languages when applicable. One workaround would be to take the list of summaries after they were generated and then apply a translation algorithm to each of them before displaying them on the frontend. This could be from English to French, German to Portuguese, Chinese to English etc.
Conclusion
While there are still improvements to be made in the field, some implementations have shown potential.
My experience with TextRank is that it has been been reliable in generating phrases through extractive summarization. This is mostly applicable to social media: occasionally a user would directly quote a phrase from an article that he/she feels would resonate with the audience.
However, this does not mean that abstractive summarization should be excluded from this domain. Until there is significant progress made, it might be useful to generate ‘tl;dr’-type posts for a user’s followers to read.
For now, the release of the general purpose T5 model from Google may be a step in the right direction towards meaningful summarization.