Project: My Attempt to create an Instagram Content Generator
During February and March, I set out to build a project to solve a problem. To say the least, the problem has remained unsolved for years, and I feel that my first stab at it would pave the way for commercial creativity for businesses of all shapes and sizes, no matter the budget and time spent in marketing.
Allow me to describe the background context behind the project…
Problem Domain: Content Marketing
Content marketing has evolved over the past 20 years through new forms and media. The first known medium is a blog, then came video content. Later on came social media and podcasting. All forms of content are now freely available to businesses to build audiences.
One of the most popular and prevalent forms of content marketing in the last 10 years is social media marketing. With platforms including Snapchat, Tik Tok, Facebook, and Instagram, entrepreneurs and influencers can tap into networks of connected users and establish tribes, while providing value in novel ways. The two types of businesses that benefit most from this form of marketing are e-commerce stores and influencers.
In 2020, there is no doubt that there are more users active on social media than ever. While engaging users through content on social media has become a marketing necessity, the cost of creating compelling, polished content has by no question gone up. The average user is looking for content including video, gifs, photos, text, and stories. This cannot be anymore true than on Instagram, where 95 million posts are uploaded each day to compete for the attention of over 100 million users.
For established online stores, this is not an issue, but for bootstrapped founders with limited resources, they do not have the luxury to take photos or editing images.
Enter: The Instagram Content Generator
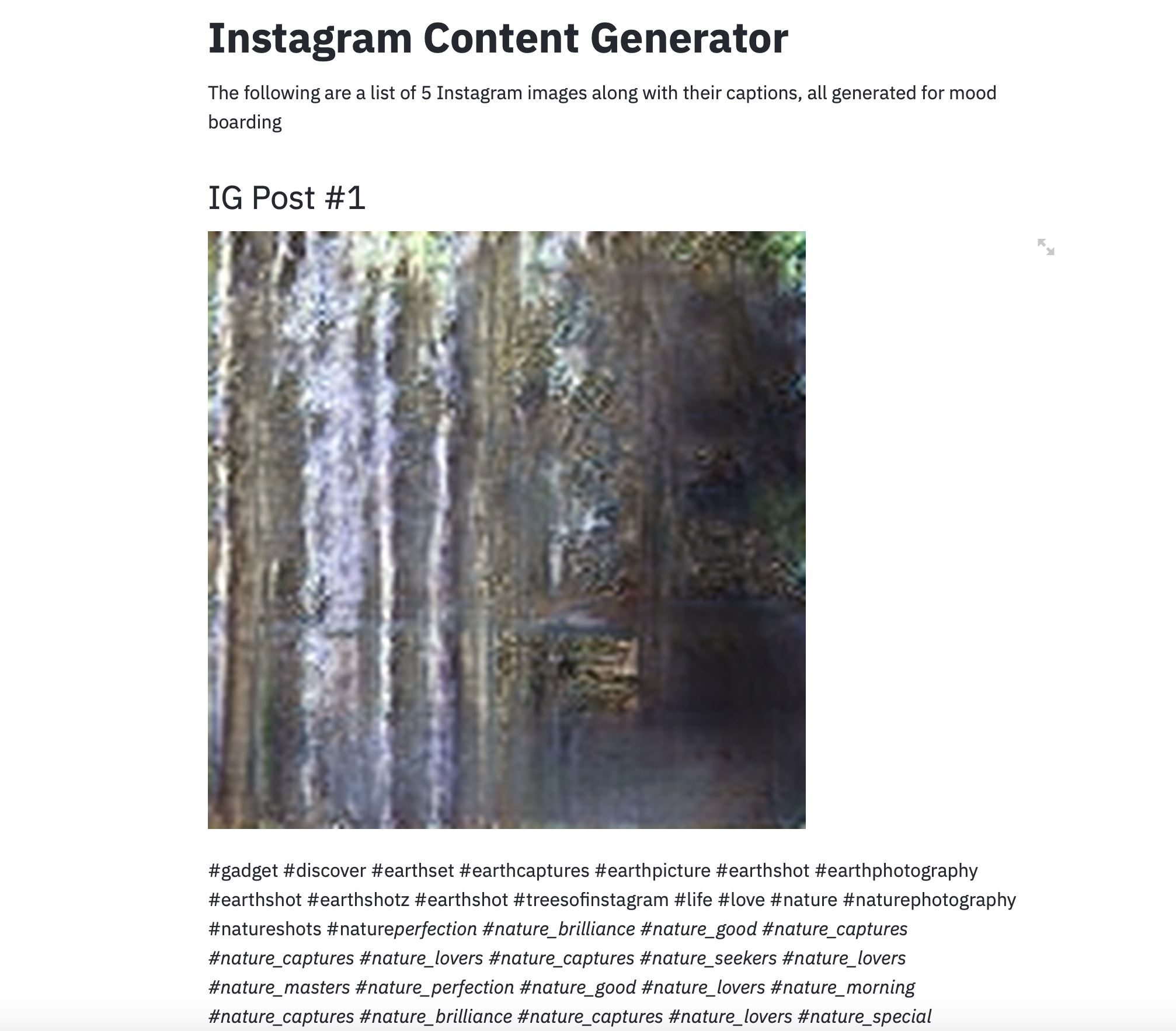
Think of this is the Content Generator v0.1.
I have come to realize this problem years ago when trying out online businesses, so I decided to create a proof of concept AI data app to help brands increase content marketing productivity on Instagram.
The data app is built with the goal of enabling businesses to grow their audiences online by auto-generating Instagram content at scale.
You can find the repository here.
You will find the demonstration of it here.
The Architecture of the Instagram Content Generator
The IG Content Generator is powered by two deep learning models: a pre-trained Generative Adversarial Network (GAN) for generating visual content, and a pre-trained GPT-2 language model for generating caption content.
The GAN used is an existing Keras implementation of a pre-trained Progressive Growing GAN (PGGAN). The PGGAN works by starting with convolutional layers that process 4x4 images. Later in the training, the PGGAN incrementally adds in new layers with images of increasing resolution, effectively “fading in” images for learning finer details in visual structures. This is the “progressive” aspect of building a GAN to generate high resolution, photorealistic images.
The GPT-2 model used is a smaller model with 124M parameters but is resource efficient. It is capable of generating near-coherent text by way of natural language modeling.
To prepare for training both models, I scraped over 20,000 Instagram posts and limited the feasibility study to tree posts, using the hashtag #treesofinstagram.
I took the images and resized them to 1024x1024 resolution to prepare them for training (the GAN is limited to training on images of a handcoded size). I then zipped them into an hdf5 file (the GAN does use Tensorflow in one of the codebases, but the implementation is mainly Keras) so the GAN could begin training on it. The GAN was trained for 10000 epochs, with model snapshots saved every 10 epochs.
I used a cloud platform to train the GAN with the dataset using a Tesla V100. The process took 1 day and 14 hours to completely train with a final model outputted at the end. As part of the experiment, I trained both with and without pre-trained weights that were previously trained on the celebA HD dataset, and the quality of the outputs turned out to be roughly the same.
For the GPT-2 training, I took all the captions that I scraped and I combined them into a single text file. This is because applying the GPT-2 on 20,000+ text files for training was unnecessarily long. I then trained the GPT-2 on the text file using a jupyter notebook on Google Colab. In contrast to the GAN training time, the GPT-2 training time took 2-3 minutes to generate a model.
With both models trained, I wrote a small data app to display the auto generation of visual and text content. This app was then deployed into a containerized environment for usage and reproducibility.
Limitations and Challenges
Generative Adversarial Networks have only emerged in the mid-2010s, and it wasn’t until 2017 that we have started to see state-of-the-art results. Up to this time, it is still incredibly difficult to replicate such results that are shown in GAN research papers.
The pre-trained PGGAN has been capable of generating somewhat plausible images of trees, but it is not capable of generating photorealistic images. This is due to several reasons:
1) I did not have access to the same type of hardware used by the teams that created the high-resolution GANs. The hardware requirements are otherwise expensive to attain or incompatible with the environment that I use for implementing the project.
2) there are multiple code implementations and most of them are difficult to understand. Some documentations describe empirical instructions for reproducing such results but they may leave out certain details that otherwise would have been helpful to the machine learning practitioner. Furthermore, there are no official GAN modules to use that are available for efficient and rapid training.
3) I had to train the GAN separately from the GPT-2. This is because I wanted to generate captions that accompany the images, but there are currently no image-to-text generation models that mimic the language of the captions corpus.
Deployment is Tough Business
Another major limitation I encountered is the ability to deploy the data application to production, end-to-end. Building the IG Content Generator meant that larger assets are required for the app to run: h5 model files that were trained earlier on 20,000 images, and language model files that were trained on captions take up 80+% of the repo space, including a folder that wasn’t included in the repo as I had exhausted the quota provided by the git LFS service. If we consider the GAN and GPT-2 model file sizes, they add up to more than 1 GB.
The size of both GAN and GPT-2 model files made it difficult to push the app to production. I had considered deploying the app to Heroku without the container but Heroku has a slug limit size of 500 MB. Even if I remove other files from the repo, it is not enough to reduce the slug size to an acceptable level for the app to be deployable.
Thus, I deployed the app to Docker. The advantage of using a containerized application is that it allows any user to run the application immediately on her computer without needing to manually install dependencies. However, after containerizing the application, I attempted to deploy it to Heroku once again, this time through its Container Registry. I created the application in production, but it still fails:
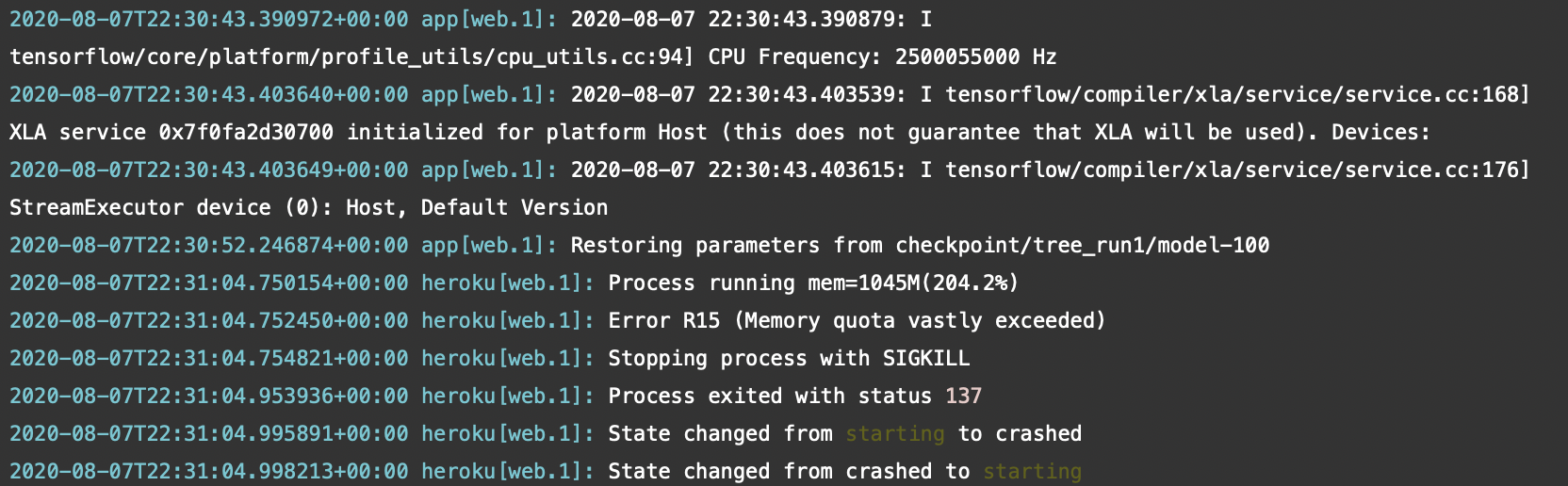
Heroku’s free tier infrastructure does not have enough resources to accommodate the IG Content Generator’s compute needs. As seen in the heroku logs above, the app’s usage far exceeded Heroku’s memory quota and the app crashed.
In the development environment, the application can be restarted multiple times to generate Instagram images and captions. In the containerized environment, the application would crash upon a single restart:
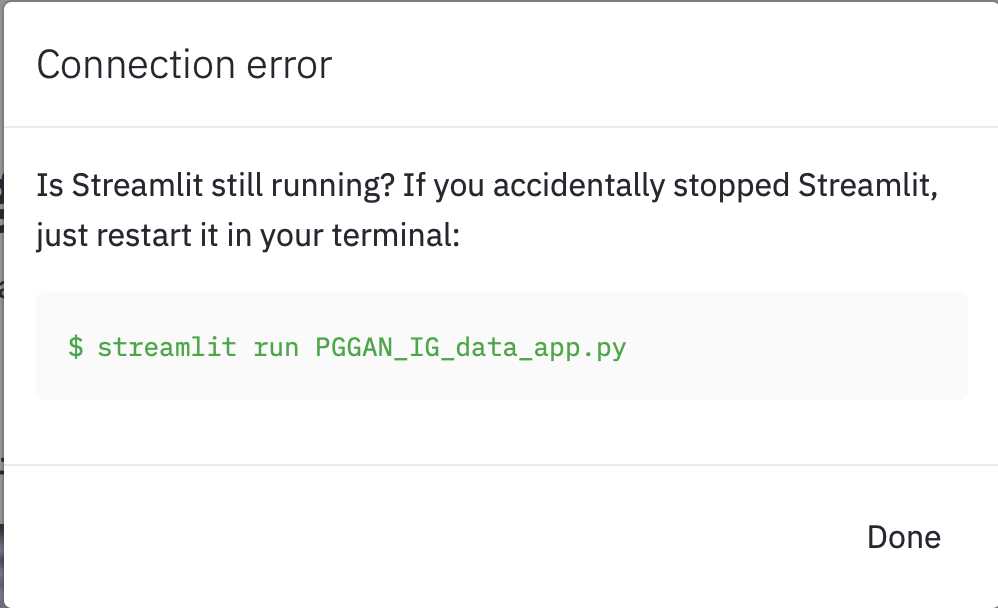
While running the app, the docker logs showed that the application exceeded 10% of the memory available, it is likely that the memory provided by the container may have reached capacity, leading the app to quit. For this reason, I have made the project available for use in development environment as instructed in the repository.
If you use the Dockerized application, you may notice that the app generates content as soon as it loads. I had attempted to create a button to offer user control in generating content, however while this worked in development environment, it too suffered from crashing in Docker.
Ideas for Improvement
Until GANs continue to advance and evolve, the capabilities are not fully available to easily generate polished Instagram posts. However, I plan to improve on this project when there is potential to experiment with new GANs that make up for the shortcomings that I have encountered, while accessing hardware to reproduce results from GAN research papers. I also plan to expand the number of use cases by training the generator on different types of content, such as promotional posts and product posts, and content of other formats such as Instagram stories.
Future plans for improving capture generation include restricting the number of hashtags to 30 and removing duplicates. Instagram currently does not allow users to add more than 30 hashtags to posts or comments. It is critical to refine the use case to align with Instagram’s policies.
The project is currently available in the form of a data app, but a possible next step would be to deploy the models into a web application and mobile application. This enables brands to accordingly select and generate a type of content of their choice before sharing on Instagram, which calls for more scraping.
Plans for improving deployment process should not be neglected either. There are two possible routes. One, I consider deploying on other cloud platforms including Azure and AWS. The two platforms offer greater variety of options for hosting containerized applications in the cloud, however they both charge rates depending on the quantity of resources used. Two, as I wrote the application in Streamlit, Streamlit is on its way to roll out its own deployment solution - Streamlit for Teams. At this time in writing, it is not available yet, but it may potentially be a faster and efficient route to deploying data applications. Time will tell when it arrives, as I look forward to testing out Streamlit for Teams and how well it will improve the deployment workflow.
I feel that up to this time, the development and deployment process has yet to be streamlined for machine learning practitioners to deploy models at scale for highly complex domains, such as generative adversarial networks, but it may take a few years for such practices to mature.
Conclusion
While version 0.1 is far from the expected quality, the IG Content Generator demonstrates the ability to generate social media content on demand.
As platforms like Instagram have become increasingly crowded with content, it is more important than ever for new businesses to grow audiences and build brand equity. Users of Instagram have become used to the professional, polished quality of a piece of visual content, yet there are brands that have not fully mastered the platform due to limited resources.
In order for new businesses to deliver value in the marketplace, there needs to be an AI-powered content generator that can scale audience building. This could bring opportunities for brands to properly allocate resources in areas that are necessary for value delivery, no matter their budgets or sizes.